
Towards Better 3D Reconstruction: Learning Reconstruction Functions from Synthetic Depth Maps
Published on September 11, 2017
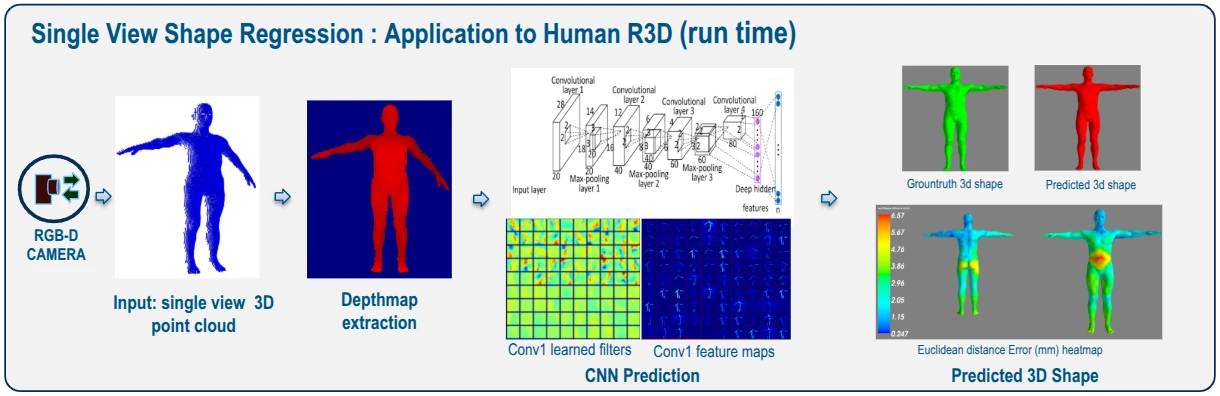
In my work, I tackled a key challenge in 3D vision: how to reliably reconstruct a 3D modeled object from a single depth map. While many systems exist to extract geometry from depth sensors, achieving robust reconstruction across varied shapes and poses remains difficult.
To address this, I invented and patented a method for learning a reconstruction function by building a synthetic dataset of depth maps paired with 3D models. The goal is to train a function that takes a depth map as input and produces a 3D model that faithfully represents the object’s 3D shape — not only in geometry but also in pose and variability.
You can review the full patent here:
US20180077400A1 – 3D Reconstruction of a Real Object from a Depth Map.
The Core Idea
The heart of this invention is simple but powerful: learn the reconstruction function from a database of synthetic data, instead of relying solely on hand-crafted analytic solutions.
In traditional depth-based reconstruction methods, a depth map captured from a sensor is processed through geometric algorithms to infer a 3D surface or model. However, these methods often struggle when depth data is noisy, incomplete, or when objects have rich pose variations.
My approach builds a parametric model of the object class (e.g., human bodies, deformable shapes) and uses that model to generate a diverse, labeled synthetic dataset of depth maps paired with corresponding 3D modeled shapes. This dataset then forms the basis for learning a reconstruction function that generalizes to real input depth maps.
The method covers two phases:
- Database creation — systematically generate a set of synthetic 3D models with controlled shape and pose variations, render corresponding depth maps, and associate each depth map with the exact 3D model that produced it.
- Function learning — use this dataset to learn a mapping from depth map to 3D model representation, so that at run-time, we can reconstruct a 3D object given only its depth map. :contentReference[oaicite:1]{index=1}
Why Synthetic Data Matters
Real world depth maps suffer from noise, partial occlusion, and unpredictable variation due to lighting and sensor characteristics. Collecting a large dataset of real depth maps with ground-truth 3D shapes is expensive and often impractical.
By generating synthetic depth maps from a parametric model:
- I can control shape and pose systematically
- I can generate arbitrarily many examples
- I can ensure accurate ground truth associations
Each synthesized depth map is computed from a virtual viewpoint using the parametric model, and — if desired — perturbations or noise (e.g., Gaussian noise) can be added to better reflect sensor behavior. :contentReference[oaicite:2]{index=2}
This leads to a dataset that captures the variation of the object class across shape, pose, and viewpoint, while maintaining exact ground truth for learning.
Parametric Modeling of Real Objects
At the heart of the method is a parametric 3D model that represents a class of real objects — for example, the shapes and poses possible for a human body.
These models typically include:
- Shape parameters — controlling the underlying morphology
- Pose parameters — controlling orientation and articulation
By varying these parameters, we synthesize thousands of distinct 3D shapes and poses. For each, we:
- Generate the 3D modeled object
- Render its depth map from a virtual viewpoint
- Add controlled noise or perturbations if desired
- Store the depth map with its associated 3D model
This database becomes the training corpus for learning the reconstruction function. :contentReference[oaicite:3]{index=3}
Learning the Reconstruction Function
Once the dataset is built, the next step is to learn a function that predicts the corresponding 3D model from a depth map.
This function could be implemented using:
- neural networks
- regression models
- geometric embedding techniques
The key is that it is trained on paired examples — depth maps and their known 3D models — so that it learns the underlying correlation between 2D depth structure and full 3D geometry.
At runtime, the learned function accepts a depth map as input (e.g., from a depth sensor or structured light camera) and outputs a 3D representation that captures both shape and pose.
Benefits and Applications
This learning-based approach to depth-to-3D reconstruction has several practical advantages:
- Generalization — trained on diverse synthetic examples, the function can generalize to depth maps for unseen shapes and poses.
- Efficiency — once learned, the reconstruction function can be efficient at runtime, suitable for real-time applications.
- Scalability — synthetic data can be scaled far beyond what is feasible with real capture campaigns.
Applications include:
- augmented reality object reconstruction
- robotics perception
- 3D avatar creation
- digital twin generation
By constructing the training process around a learned function and synthetic depth database, we remove the dependence on handcrafted geometry algorithms alone.
Final Thoughts
The method claimed in my patent moves beyond traditional analytical reconstruction by embracing a data-driven paradigm, where controlled synthetic examples enable learning of a function that can tackle real-world variability with robustness.
This approach reflects a broader trend in computer vision: leveraging synthetic data and learned models to achieve performance that outstrips classic analytic techniques.