
3D Morphable Face Models and Dense Landmark Fitting on Mobile
Published on January 16, 2019
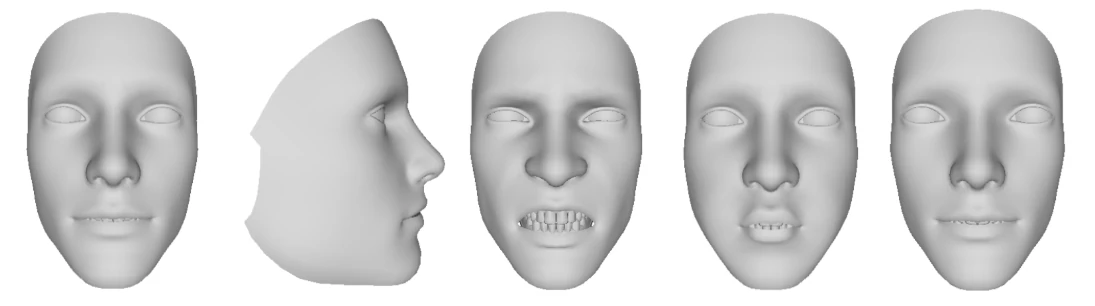
3D Morphable Face Models (3DMM) have become a cornerstone of modern face analysis, enabling robust 3D-aware understanding of faces from sparse 2D observations.
While often associated with offline reconstruction or research prototypes, lightweight 3DMM pipelines can now run on mobile devices, enabling dense face representations in real time.
This article presents a PCA-based 3D Morphable Face Model and explains how I perform dense face landmarks alignment by fitting the model to sparse 68-point landmarks using a mobile-friendly C++ implementation on Android.
1. What Is a 3D Morphable Face Model (3DMM)?
A 3D Morphable Face Model represents human faces as a parametric deformable mesh.
Instead of predicting geometry directly, the face is expressed as a linear combination of learned basis shapes, allowing:
- Compact representation
- Smooth deformations
- Strong statistical priors
At its core, this is a Point Distribution Model (PDM) learned using Principal Component Analysis (PCA).
2. PCA-Based Shape and Expression Modeling
The face geometry is decomposed into three components:
\[\mathbf{V} = \mathbf{\bar{V}} + \mathbf{B_s}\alpha + \mathbf{B_e}\beta\]Where:
- $(\mathbf{\bar{V}})$ is the mean face
- $(\mathbf{B_s})$ are shape blendshapes
- $(\alpha)$ are shape coefficients
- $(\mathbf{B_e})$ are expression blendshapes
- $(\beta)$ are expression coefficients
Model Characteristics
This particular 3DMM has the following properties:
- 4,556 vertices
- 210 PCA shape blendshapes
- 52 expression blendshapes
- Expressions are ARKit-compatible
- Model stored as a binary file for fast loading
This design strikes a balance between geometric fidelity and runtime efficiency, making it suitable for mobile deployment.
3. Why ARKit-Compatible Expression Blendshapes?
Using ARKit-compatible expression blendshapes offers major advantages:
- Direct mapping to industry-standard facial semantics
- Easier integration with animation, avatars, or AR pipelines
- Interoperability with existing face tracking systems
Expressions such as jaw open, brow raise, eye blink, or mouth shapes are encoded explicitly, rather than implicitly learned.
4. Binary Model Format: A Mobile-First Choice
The 3DMM is stored as a binary file, not as text (OBJ / JSON / XML).
This is critical on mobile:
- Faster loading
- Lower memory footprint
- No parsing overhead
- Deterministic layout
On Android, this allows:
- Memory-mapped I/O
- Zero-copy loading where possible
- Predictable startup time
5. From Sparse to Dense: Face Landmark Fitting
Most mobile face detectors output sparse landmarks, typically 68 points.
These landmarks alone are not sufficient for:
- Dense geometry
- Accurate surface normals
- Consistent face topology
The solution is model fitting.
6. Dense Face Landmarks via 3DMM Fitting

Dense face landmarks are obtained by fitting the 3D Morphable Model to sparse 2D observations using an iterative optimization process.
Rather than predicting geometry directly, the system estimates a Local and global 3DMM parameters that explain how the 3D face model should deform and how it should be positioned in the camera.
Local vs Global Parameters
The optimization produces two distinct categories of parameters:
Local Parameters (Non-Rigid Shape)
These parameters describe how the face deforms:
- Shape coefficients (PCA-based identity deformation)
- Expression coefficients (ARKit-compatible facial expressions)
They capture:
- Individual facial morphology
- Facial expressions (mouth, eyes, brows, jaw, etc.)
These parameters are non-rigid and vary independently of head pose.
Global Parameters (Rigid Transformation)
These parameters describe how the face is positioned in 3D space relative to the camera:
- Scale
- Euler rotations:
euler_x(pitch)euler_y(yaw)euler_z(roll)
- Translation:
tx,ty
Together, they define a rigid transformation applied to the 3D face mesh before projection.
Optimization Objective
The fitting process minimizes the reprojection error between:
- The observed 68 sparse 2D landmarks
- The corresponding projected landmarks derived from the dense 3D mesh
Each 2D landmark is associated with a fixed vertex (or barycentric location) on the 3D face model.
Gradient-Based Iterative Optimization
A gradient-based optimization method is used:
- Initialize shape, expression, and pose parameters
- Apply non-rigid deformation (local parameters)
- Apply rigid transformation (global parameters)
- Project the 3D landmarks into 2D image space
- Compute the landmark distance error
- Update parameters using gradients
- Iterate until convergence
Mobile-Oriented Design
The optimization is deliberately kept lightweight:
- Small parameter space
- Few iterations
- Analytic or semi-analytic gradients
- No heavy nonlinear solvers
This allows:
- Real-time execution on Android CPUs (30+ FPS)
- Deterministic behavior
- Stable convergence across frames
Output of the Fitting Process
At convergence, the system outputs:
- Dense 3D face mesh (4,556 vertices)
- Local parameters (shape + expression)
- Global parameters
[scale, euler_x, euler_y, euler_z, tx, ty] - Dense face landmarks derived from the fitted mesh
These outputs form a compact and expressive representation of the face, suitable for downstream tasks such as tracking, animation, or driver state analysis.
7. Why Lightweight Fitting Matters on Mobile
Mobile constraints are unforgiving:
- Limited CPU budget
- No guaranteed GPU access
- Thermal throttling
- Battery impact
The fitting approach is designed to:
- Run fully in C++
- Avoid dynamic memory allocations
- Use small dense linear systems
- Be deterministic frame to frame
This makes it compatible with:
- Android NDK
- Embedded pipelines
- Long-running sessions
8. Benefits of Dense Face Landmarks
Once fitted, the 3DMM provides:
- Dense correspondence across frames
- Pose-invariant facial representation
- Robust tracking under occlusions
- Clean separation of shape vs expression
Compared to raw 2D landmarks, this enables:
- Head pose estimation
- Expression analysis
- Face reenactment
- AR overlays
- Driver or user state analysis
Here is an example of a face image animation I created using this method on mobile. Photo animated based on GLSL code:
9. Final Thoughts
3D Morphable Face Models are often seen as heavyweight or academic tools.
In reality, with:
- A compact PCA-based model
- ARKit-compatible expressions
- Binary serialization
- Lightweight fitting
They become practical, production-ready components, even on mobile devices.
Dense face landmarks derived from a fitted 3DMM provide a stable, interpretable, and geometry-aware foundation that sparse landmarks alone cannot offer.